Introduction
Linux has common utilities such as List files (ls), remove files (rm), find files (find), change file permissions (chown, chmod), and copy (cp). Developers, admins or other users of Linux systems use these utilities on a daily basis. Designed to work on mounted file systems, these utilities are also quite useful while writing Shell scripts to automate work. They work with disk-based and network-based file systems. Their usage in case of network files system is by mounting the network file systems (e.g. NFS) to a local directory. The utilities are executed on the local mountpoint. The file system driver on the system helps execute the utilities.
Let’s discuss some advantages and disadvantages of using the mounted approach to run Linux utilities for network file systems.
Advantages:
- No need to change existing Linux utilities
- The quick development of tools/scripts around them
Disadvantages:
- Linux utilities are basically single-threaded applications
- Every operation has to go through a whole file system stack of the operating system
- Not efficient for all type of workloads, especially parallel data processing
What is LIBNFS?
LIBNFS is a client library for accessing NFS shares over a network. Check out this project at https://github.com/sahlberg/libnfs. LIBNFS offers three different APIs, for different use cases:
- RAW: A fully asynchronous, low-level RPC library for NFS protocols
- NFS ASYNC: A fully asynchronous library
- NFS SYNC: A synchronous library
Any of the Linux utilities (ls, cp, etc) can be developed with different types of APIs provided by libnfs, which allow you to run without mounting the NFS share point. It gives the flexibility to create multiple connections to the NFS server. Multiple connections enable a utility to handle any operation in parallel and without going through the file system stack.
Parallel Copy (PCP)
Let’s consider the case of parallel copy utility, which is similar to the CP utility (http://man7.org/linux/man-pages/man1/cp.1.html) in Linux. As we know, the primary work of CP is to copy data from a source directory to a destination directory. Linux CP supports a lot of functionalities around copy operation, but we will not be discussing that. We will focus on how parallel data copy is done for NFS.
Take the case of copying massive data (in hundreds of TB) from one NFS server to another. A copy could be due to migration of data or replication use cases. Modern NFS servers could be of type scale-out or parallel NFS and underline storage could be of Flash storage type. These types of storage support multiple connections to a server. To leverage this type of NFS storage, we also need utilities to take advantage of it.
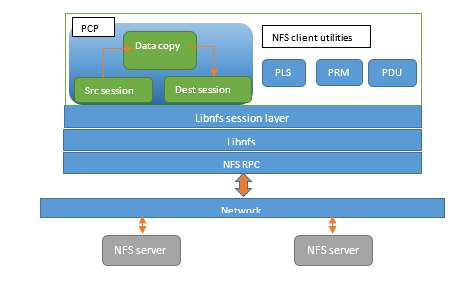
A typical high-level design for any parallel utility could be as shown in the diagram below:
Connection
Each connection is a communication endpoint between the PCP utility and the NFS server. It uses the NFS context from LIBNFS. The portmapper service takes care of providing an NFS connection.
Sessions
A session is a logical collection of the NFS connection. Typically, both the source and destination NFS servers have one session each. PCP reads data from the source session and writes to the destination session. The read/write calls internally need to distribute to connections to achieve parallelism.
Multi-threading
Because there are multiple connections and massive data to process, using multi-threading in the PCP utility is required. One approach could be to use a thread pool across a session or one thread per connection. An IO request could be distributed to threads and connections without starving or overloading either. This is up to the implementer.
Conclusion
- Leveraging the storage capacity to achieve massive parallel data copy is possible.
- PCP can support a CP-like option from the main page so that the existing tool/scripts can be used with PCP too.
- Utilities such as PLS, PRM would be just metadata operations, which will have simpler and parallel implementations.





