“The goal is to turn data into information, and information into insight.”
This powerful quote by Carly Fiorina, Former CEO of Hewlett-Packard, is by far one of my favorites when it comes to data engineering.
The overall goal of data engineering services is not limited to managing data but enabling businesses to build data-driven innovations and solutions. As data is growing faster than the speed of light, industries are trying to put their best foot forward to harness their ability and gain a competitive advantage in the market. Today, data engineering is branching into distinct and innovative domains, spanning from traditional data warehousing to embracing the goodness of real-time data processing, cloud-based solutions, advanced analytics, and a lot more. This evolution, led by the exponential increase in demand for scalable, effective, and actionable data insights, is changing the digital landscape like before.
According to a report by Mordor Intelligence, edge computing that facilitates data processing closer to its source, is expected to reach $50.34 billion by 2027. These numbers signify the need for data engineering services, to manage, and process data at the edge, optimize response times, and improve data handling capabilities.
Considering the underlying potential of data engineering services in helping organizations optimize their data infrastructure, and make impactful decisions, this blog is curated to cover everything modern businesses need to know about data engineering.
Understanding the essence of data engineering
Data engineering is the process of designing and developing systems for storage, analysis, and aggregation of data at scale. These services predominantly empower businesses to garner valuable insights in real time from large datasets.
Right from social media metrics to employee performance stats to trends, and forecasts, enterprises have all the data at their fingertips to get a holistic view of business operations. By transforming humungous amounts of data into valuable insights and strategic findings, businesses can leverage data engineering services to access datasets at any given point in time securely.
By leveraging reliable data engineering services, businesses can have access to more than one data type, to make crucial and well-informed decisions. Data engineers on the other hand are responsible for governing data management for downstream usage like forecasting, analysis, and more.
In a nutshell, data engineering is a practice that is mission-critical for the modern data platform and makes it possible for businesses to analyze and apply the data they receive, regardless of the data source or format.
To get a better grip on the concept of data, you can also explore our blog on Computational Storage: Pushing the Frontiers of Big Data
Core components of Data Engineering
The image below gives a quick overview of the core components of data engineering. The table below is curated to include these and a few more concepts that are at the heart of data engineering.
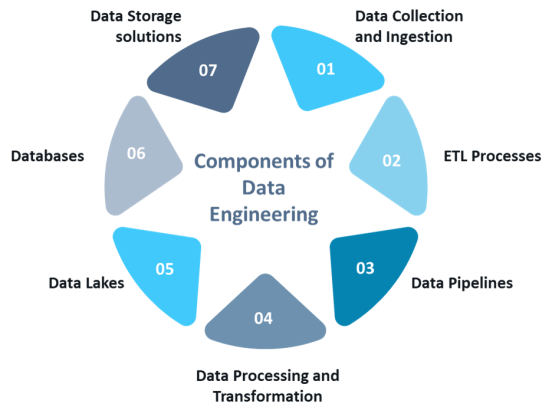
Core Components of Data Engineering
| Concept | Description |
| Data Collection and Ingestion | Data collection and data ingestion are two critical aspects of data management, that aid businesses to gather and make effective use of data. These two concepts often are conflated, but on the broader front, they serve different purposes. Data collection is a process that gathers information from a variety of sources, whereas data ingestion is involved in importing that data to a system where it can be processed and analyzed. |
| ETL Process | ETL also known as Extract, Transform, and Load is a comprehensive process that combines data from different sources into a data warehouse and uses business rules to perform actions like cleaning and organization of raw data to make it storage, analytics, and machine learning ready. |
| Data Pipelines | Data pipeline is a technique that ingests and transforms raw data acquired from different sources and transports it to a data repository like a data lake or a data warehouse for further analysis. |
| Data Processing and Transformation | Data processing and transformation are activities that make data extraction possible from different systems and help merge, clean, and deploy it for data analysis. |
| Data Lakes | A data lake is a central repository that accommodates humungous volumes of data in the naive and raw format. In comparison to the hierarchical data repository, which stores data in formats like files and folders, data lakes operate on a flat architecture. |
| Databases | In simple terms, databases are nothing, but a collection of data stored electronically and organized in a systemic format. Often stored in a single location, databases enable organizations to access, manage, and modify the information collected. |
| Data Storage Solutions | Data storage solutions are designed to store data in electronic format in a way that makes it machine-readable. |
| Data Modeling | Data modeling is a process of analyzing and identifying different data types collected by businesses. By deploying texts, diagrams, and symbols, data models can create a visual representation of how data is collected, stored, and used by your business. |
| Data Engineering Lifecycle | The data engineering lifecycle is a process that covers aspects related to the entire process of converting raw data into a meaningful product. This process involves five stages that are supported by predominant principles like data architectures, dataOps, software engineering, etc. |
| Data Warehousing | A data warehouse is a system extensively used for analyzing and reporting structured and semi-structured data received from a range of sources such as point-of-sale systems, CRM, marketing automation, and more. This system is adept at storing both current and historical data at a single location and is engineered to give a strategic perspective of data making it one of the key components of business intelligence. |
Technologies and tools in data engineering
As the technology space rapidly expands, data engineering has also evolved to efficiently manage and process large volumes of data for valuable business insights. However, delivering quality data engineering services largely depends on the types of tools and technologies that are deployed to align with business needs and goals.
Mentioned below are a few of them:
Python: Python is a highly popular choice among data engineers. Its features like agility, user-friendly aspects, and powerful libraries, help engineers streamline coding efforts.
SQL: Next up is SQL, also known as Structured Query Language, which is a standard for accessing and managing relational databases. It is an essential tool for querying and manipulating structured data.
PostgreSQL: is an open-source relational database management system that unites the potential of relational databases and blends it with the agility quotient of object-oriented programming.
MongoDB: NoSQL, like MongoDB, is one of the most sophisticated platforms used for unstructured or semi-structured data, which a common in new applications. This technology offers a flexible approach that is much needed for cloud applications that demand high performance and scalability.
Other than these technologies like JSON, Apache Spark, and Apache Kafka make a strong arsenal of tool technologies to accelerate and enhance the performance of data engineering services.
Data Engineering Lifecycle
The data engineering lifecycle is the comprehensive process responsible for turning raw data into a usable form making it user-ready for professionals like data scientists, machine learning engineers, and analysts. The lifecycle primarily consists of five stages viz, generation, ingestion, transformation, serving, and storage. Apart from that it touches six core elements such as security, data management, data, data architecture, orchestration, and software engineering.

Core Elements of Data Engineering Lifecycle
Security
This is the most important aspect for data engineers at every stage to make data accessible only to authorized entities. Here the principle of least privilege is leverage, to enable users to access only what is necessary and strictly for a set duration.
Note: To maintain security, data is often encrypted as it moves from one stage to another.
Data management
Data management is a concept that provides a framework keeping in mind the overall perspective of data usage across the organization. It covers elements such as data governance, data modeling, and lineage to meet ethical considerations. Here the broader goal is to sync the data engineering processes to adhere to organizational policies related to legal, financial, and cultural aspects.
DataOps
DataOps leverages principles from Agile and DevOps methodologies to improve data quality and release efficacy. It basically blends people, processes, and technologies to deliver improved collaboration and rapid innovation.
Data Architecture
Data architecture is like a structure that supports the long-term goals of an organization. This includes a clear understanding of the alternatives and making informed decisions about design patterns, tools, and technologies responsible for balancing the act of cost and innovation.
Software engineering
As data engineering is becoming more intelligent and tool-driven, data engineers are required to stay updated and skilled to write code in different languages and frameworks. They must also use effective code-testing practices and occasionally address unique coding challenges outside of standard tools, particularly when managing cloud infrastructure through Infrastructure as Code (IaC) frameworks.
Unfolding the main stages of the data engineering lifecycle
Generation
This is the primary step where the source system is any given origin of data that outputs raw data that can be used later. These can be available in an array of formats such as IoT devices, transactional data, RSS feeds, flat files like CSV or XML, and more.
Data Ingestion
Data ingestion is a stage that signifies the collection of data from different generating sources into a processing system. In the push model, data is actively transferred from the source system to the target destination. On the other hand, a pull model is where the destination system requests and retrieves data from the source. The significant difference between these two models blurs as data transits through several stages in the pipeline, making effective management of data ingestion mission-critical to maintaining a smooth flow and preparation of data for future analysis.
Data transformation
In this stage, raw data is refined by using operations that can improve its quality and utility value. For instance, this step normalizes the values to a standard scale, fills gaps on occasions of missing data, converts between data types, and more to extract specific data features. The goal here is to shape data into a more structured and standardized format ready for analytical operations.
Data serving
This is the final stage in the lifecycle that makes available processed and transformed data for end-users, downstream processes, or apps. This is usually accomplished via structured formats, by deploying APIs to make sure data is accessible. The goal is to deliver well-timed and reliable data that has the potential to meet an organization’s analytical, reporting, and operational requirements.
Data Storage
Data storage is one of the core technologies that stores data through a range of data engineering stages. It is a concept that helps connect diverse and frequently siloed data sources, with their own unique data sets, structures, and formats. Storage merges disparate data sets to deliver a more organized and reliable data view. The aim is to guarantee that data is reliable, secure, and readily available.
Emerging trends in data engineering
So, what’s next in data engineering? Let’s have a quick overview:
Emerging trends in data engineering are reshaping the field with notable advancements. AI-driven automation is enhancing data workflows and reducing manual errors, while real-time data streaming technologies like Apache Kafka enable instant insights. The rise of data mesh promotes decentralized data management, and cloud-native tools offer scalability and flexibility. Privacy-enhancing technologies ensure data protection and edge computing optimizes IoT data processing. Integrating DataOps and (Machine Learning Operations) MLOps streamline data and ML model lifecycles, while cross-platform data integration facilitates seamless data movement across diverse environments.
Download our latest whitepaper to gain insights that can drive your cloud-native strategy forward and enhance your data streaming capabilities.
StreamNative Cloud vs Amazon MSK
Key Takeaways
Data engineering is crucial for modern businesses as it underpins effective data management and drives actionable insights. By structuring and processing data efficiently, data engineering enables organizations to harness large volumes of information from various sources. This capability is essential for generating real-time insights, supporting data-driven decision-making, and maintaining competitive advantage.
Effective data engineering practices streamline workflows, ensure data quality, and integrate complex systems, which helps businesses respond swiftly to market changes and evolving needs. Additionally, it supports scalability through cloud-native solutions and enhances security with privacy-focused technologies. As data continues to grow in importance, robust data engineering not only optimizes operations but also unlocks new opportunities for innovation and growth.
Calsoft being a technology-first company, can completely relate to the importance of data for any business. In the ever-evolving world of technology where data is the new gold, cloud-based systems play a significant role in aptly managing the surge in data generation. Remember, the more the data, the higher its usage in heterogeneous systems. As complexities in data increase, there is a dire need for Efficient Data Management. Calsoft’s data engineering services are curated to enable businesses to extract meaningful and valuable insights from all their data sources.





