Big data technologies and their applications are stepping into mature production environments. Many storage startups have jumped onto the bandwagon with the availability of mature, open source big data tools from Google, Yahoo, and Facebook.
This blog covers big data stack with its current problems, available open source tools and its applications. Processing large amounts of data is not a problem now, but processing it for analytics in real business time, still is. The availability of open sourced big data tools makes it possible to accelerate and mature big data offerings. This blog introduces the big data stack and open source technologies available for each layer of them. As big data is voluminous and versatile with velocity concerns, open source technologies, tech giants and communities are stepping forward to make sense of this “big” problem.
- Introduction
- Big data
- Why is big data a problem?
- Big data stack explained
- Open source tools
- Why open source tools?
- Parameters to consider for choosing tools
- Open source tools available for big data
Introduction
What is Big Data?
Big data is an umbrella term for large and complex data sets that traditional data processing application softwares are not able to handle. Large scale challenges include capture, storage, analysis, data curation, search, sharing, transfer, visualization, querying, updating and information privacy within a tolerable elapsed time.
Big data consists of structured, semi-structured, or unstructured data. The three types of data are structured (tabular form, rows, and columns), semi-structured (event logs), unstructured (e-mails, photos, and videos). For big data analysis, we collect data and build statistical or mathematical algorithms to make exploratory or predictive models to give insights for necessary action.
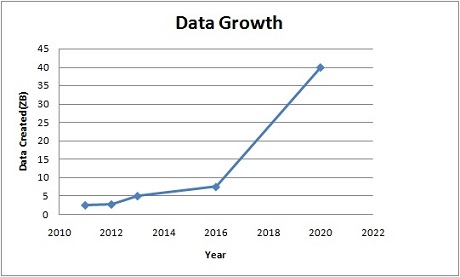
Big data is growing fast. For example, users perform 40,000 search queries every second (on Google alone), which makes it 1.2 trillion searches per year. There is a massive growth in video and photo data, where every minute up to 300 hours of video are uploaded to YouTube alone[sourceforce.com]. The Internet of Things also generates a lot of data (sensor data). All this data is generated massively in a short span of time. For this data, storage density doubles every 13 months approximately and it beats Moore’s law.
The Vs explain this very efficiently and the Vs are Volume, Velocity, Variety, Veracity, and Variability. If the data falls under these categories then we can say that it is big data.
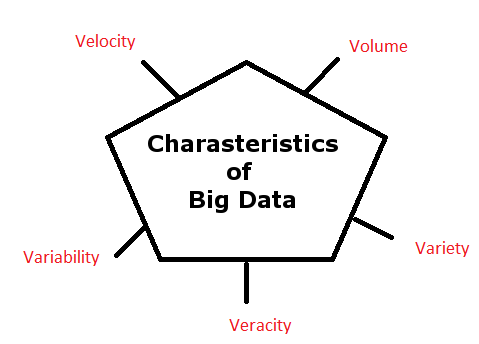
Volume – According to analysis, 90% of data has been created in the past two years. It is difficult to store peta bytes of data in RDBMS (IBM, Oracle and SQL) and they have to increase the CPUs and memory to scale up.
Velocity – Velocity is the data rate per second. Big data systems need to process data in real time for strategic and competitive business insights. For example, the New York stock exchange captures 1 TB of trade information during each trading session. It is also a challenge for a traditional RDBMS to process this data in real time.
Variety – There are three types of data – structured, semi-structured, and unstructured. Semi-structured data is also unstructured data. The data is derived from various sources and is of various types.

Veracity – The quality of data is another characteristic. Ingested data may be noisy and may require cleaning prior to analytics. Veracity includes two factors – one is validity and the other is volatility.
- Validity: Correctness of data is the key feature for analyzing data to get accurate results. Analyzing false data gives incorrect insights.
- Volatility decides whether certain data needs to be available all the time for current work.
Variability – The meaning of data can be different as the value within the data is changing constantly. Most of the unstructured data is in textual format. A single word can have multiple meanings depending on the context. This is an important factor for Sentiment Analysis.
Why are specialized big data tools required?
| Attributes | Traditional | Big Data | Note |
| Volume | GBs to TBs | PBs to Zeta Bytes | The amount of data is shifted from TBs to PBs. |
| Organization | Centralised | Distributed | The data is stored in distributed systems instead of a single system. |
| Data Type | Structured | Semi structured and unstructured | Today’s data consists of structured, semi-structured and unstructured data. |
| Data Model | Fixed Schema | Flat Schema | Structured data has a fixed schema while big data has flat schema |
Big Data Stack Explained
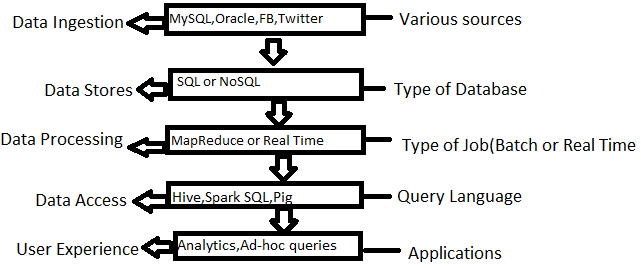
The first step in the process is getting the data. We need to ingest big data and then store it in datastores (SQL or No SQL). Once data has been ingested, after noise reduction and cleansing, big data is stored for processing. There are two types of data processing, Map Reduce and Real Time. Scripting languages are needed to access data or to start the processing of data. After processing, the data can be used in various fields. It may be used for analysis, machine learning, and can be presented in graphs and charts.
Earlier Approach – When this problem came to existence, Google™ tried to solve it by introducing GFS and Map Reduce process .These two are based on distributed file systems and parallel processing. The framework was very successful. Hadoop is an open source implementation of the MapReduce framework.
Big Data Open Source Strategies
Big companies like Google, Facebook, Twitter et al are now contributing to big data open source projects along with thousands of volunteers. There are lots of advantages to using open source tools such as flexibility, agility, speed, information security, shared maintenance cost and they also attract better talent. Since open source tools are less cost effective as compared to proprietary solutions, they provide the ability to start small and scale up in the future. Anyone can pick up from a lot of alternatives and if the fit is right then they can scale up with a commercial solution. Most mobile, web, and cloud solutions use open source platforms and the trend will only rise upwards, so it is potentially going to be the future of IT.
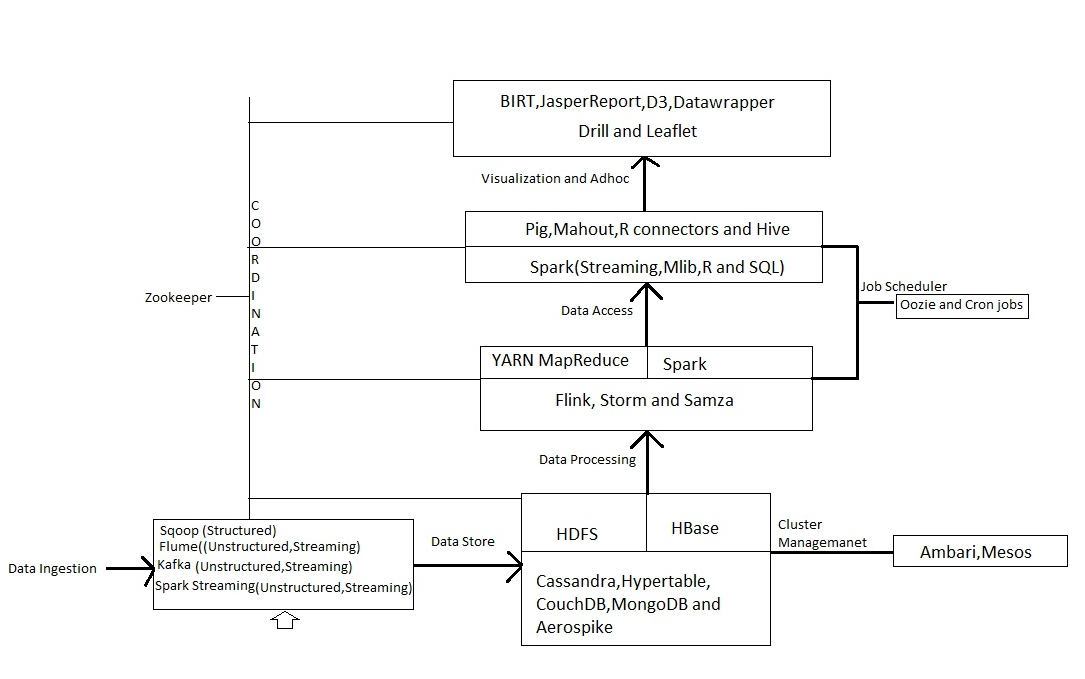
Structured data can be extracted from databases using Sqoop. Sqoop can be used for importing and exporting data from the Hadoop ecosystem. Semi-structured data is also unstructured and it can be converted to structured data through processing. Flume, Kafka and Spark are some tools used for ingestion of unstructured data. All these tools are used for streaming data as most unstructured data is created continuously.
For Hadoop ecosystem, Flume is the tool of choice since it integrates well with HDFS. Kafka is a general publish-subscribe based messaging system. It is highly scalable. It is not specifically designed for Hadoop. Its velocity is also higher than Flume. Both tools can work together and leverage each other’s benefits through a tool called Flafka. Spark streaming can read data from Flume, Kafka, HDFS, and other tools.
Once data is ingested, it has to be stored. HDFS, Base, Casandra, Hypertable, Couch DB, Mongo DB and Aerospike are the different types of open source data stores available. These are all NoSQL databases and provide superior performance and scalability. And all types of data can be handled by NoSQL databases compared to relational databases. The main criteria for choosing a right database is the number of random read write operation it supports.
After storing the data, it has to be processed for insights (analytics). For batch processing, tools such as Map Reduce and Yarn can be used, and for real time processing Spark and Storm are available. Batch processing divides jobs into batches and processes them after reaching the required storage amount. Post this, data is processed sequentially which is time consuming. In real-time, jobs are processed as and when they arrive and this method does not require certain quantity of data. It continuously consumes data and provides output.
We need to write queries for processing data and languages like Pig, Hive, Mahout, Spark(R, MLIb) are available for writing queries. SQL queries via Hive provide access to data sets. Choose the language according to your skills and purpose.
Data visualization is used to represent the results of big data query processing. There are certain tools which can be used for this. If all the tools work together then the desired output can be produced. For coordination between various tools Zookeeper is required. And for cluster management Ambari and Mesos tools are available. We can also schedule jobs through Oozie and cron jobs.
How to choose the right open source tool
There are certain parameters everyone should consider before jumping onto open source platforms. Otherwise the tool might end up being a disaster in terms of efforts and resources.
Reputation – What is the general consensus about tools and reviews from in production users?
Popularity – How popular and active is the open source community behind the technology?
Ongoing efforts – What is the technology roadmap for the next 3-5 years?
Standards – Which technical specifications does the technology qualify and which industry implementation standards does it adhere to?
Interoperability – Following standards does ensure interoperability, but there are many interoperability standards too. Big data as a service and with cloud will demand interoperability features.
Support (Community and Commercial) – Open source tools suffer when dedicated resources/volunteers are not keeping technologies up to date and commercial offerings become vital. Many a times, latest required features take years to become available.
Skill Set – Is the tool easy to use and extend?
Project Model – Open source technologies tend to cease with lesser popularity and become commercial with greater popularity. Some open source projects start off as free and many features are offered as paid or do it yourself. It is important to choose technologies that will remain open source.
Documentation – Open source tools suffer from ease of use for the lack of better documentation. But that is mitigated by an active large community.
License – Open source is free but sometimes not entirely free. Choose a tool that will continue to grow with the community.
Conclusion and Realizations:
Open source has been marred with a bad reputation and many gallant efforts have never seen the light of production. What has changed with big data open source technologies is that the biggest IT giants are putting their weight behind these technologies.
Big data and ML open source technologies are battle proven in the largest production datacenters of Google, FB, Twitter et al. As these technologies are mature, it is time to harvest them only in terms of applications and value feature additions.
Each big data stack provides many open source alternatives. It is the deployment environment that dictates the choice of technologies to adopt.
Each tool is good at solving one problem and together big data provides billions of data points to gather business and operational intelligence. Big data and machine learning technologies are not exclusive to the rich anymore, but available for free to all.
The early adopters are already reporting success. This is an opportune time to harvest mature open source technologies and build applications, solving big real world problems.
[Tweet “Primer: Big Data Stack and Technologies ~ via @CalsoftInc”]
Still, confused about choosing the right big data open source tool?





