In our previous blog Primer: Big Data Stack and Technologies, we have talked about various open source tools for Big Data stacks. Before implementing any Big Data stack in the organization, each tool in the stack is measured on the performance basis. Its performance metrics is compared to other tools available in the same stack. This is called Big Data Performance Benchmarking.
Why specialized tools are required for Big Data Benchmarking?
Big data consists of 4 V’s (volume, variety, velocity, and veracity) the main problem where the traditional tools fail to benchmark is the variety of data. Big data includes unstructured or semi structured data and it does not fit in the traditional relational table model, also the existing benchmarking tools are built around the traditional RDBMS. So there is a requirement for the specialized tool for creating real world workloads which is the main challenge in the big data benchmarking tools.
Why benchmarking is needed in Big Data?
To get insight from various types of data or workloads, a complete stack should be implemented. Without benchmarking if we implement the stack, we may not come to know its performance bottleneck. Benchmarking the big data stack gives a complete visibility of its performance as per the required specifications.
Benchmarking Big Data
There are tools available for benchmarking each Big Data stack. We will be discussing about some of them here.
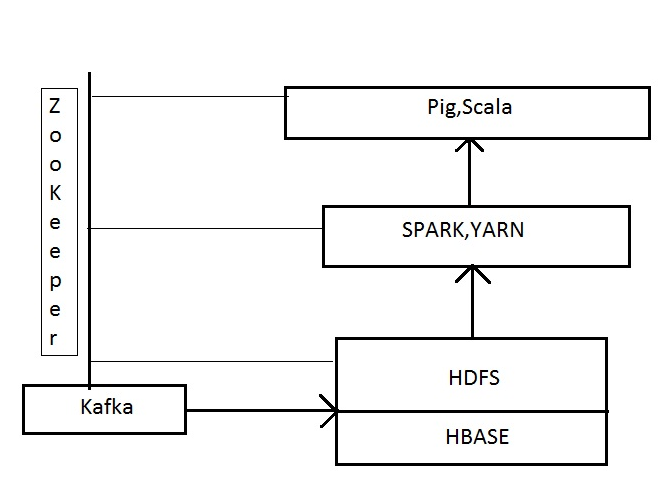
Fig: Most popular big data stacks
1. Kafka
Apache Kafka is an open-source stream processing platform developed by the Apache Software Foundation written in Scala and Java. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. Its storage layer is essentially a massively scalable pub/sub message queue architected as a distributed transaction log, making it highly valuable for enterprise infrastructures to process streaming data. Additionally, Kafka connects to external systems (for data import/export) via Kafka Connect and provides Kafka Streams, a Java stream processing library.
More about Kafka:
- It runs as a cluster on one or more servers.
- Its cluster store streams of records in categories called topics.
- Each record consists of a key, a value, and a timestamp.
To know more about Kafka, please refer the link https://kafka.apache.org/intro.html
Benchmarking Kafka
a. Scalability
Start with a single node and run the workload below –
Run – bin/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance –topic test -1 –num-records 50000000 –record-size 1000 –throughput -1 –producer-props acks=1 bootstrap.servers=localhost:9092 buffer.memory=104857600 batch.size=9000
Output: This will measure the scalability of the Kafka cluster.
b. Impact of message size
This can be done by changing the message sizes with addition of nodes.
Run – bin/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance –topic test –num-records 50000000 –record-size 500 –throughput -1 –producer-props acks=1 bootstrap.servers=habench102:9092 buffer.memory=104857600 batch.size=9000
Output: This test will give us an idea of the effect of the message size in the kafka cluster.
c. Replication expense
As all the messages are stored and storage space is involved this test will give an idea regarding the expenses we can manage for replications. Before running this test the topics should be created with the correct replication factor parameter. With no replication which is default 1 replication as replication factor cannot be zero.
Run – With Replication 1
bin/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance –topic testr3 –num-records 30000000 –record-size 500 –throughput -1 –producer-props acks=1 bootstrap.servers=habench101:9092 buffer.memory=104857600 batch.size=6000
Output: This test will verify the throughput and the messages sent per seconds as all the partions are replicated and stored.
2. HDFS
Apache Hadoop is used for distributed storage and processing Big Data dataset, using MapReduce programming model. It consists of computer clusters; built from commodity hardware. In this stack, HDFS is primarily storage, while processing is managed by MapReduce programming model.
Benchmarking HDFS
a. Teragen -Teragen creates sample data and places it in an output directory for terasort. Terasort runs through the directory and creates the reduce output on an output directory. Teravalidate ensures that terasort is reduced and mapped correctly.
b. Running Teragen –
Command – hadoop jar hadoop-mapreduce-examples.jar teragen 5000000000 /benchmarks/terasort-input // 500GB.
This creates a 500GB file in the HDFS under the /benchmarks/terasort-input folder. It’s for the terasort to run its benchmarking.
c. Running terasort –
Command – hadoop jar hadoop-mapreduce-examples.jar terasort /benchmarks/terasort-input /benchmarks/terasort-output.
This command runs a benchmarking MapReduce job on the data created by Teragen in the /benchmarks/terasort-input folder. The output of this is written into files and placed under the /benchmarks/terasort-output/ folder, where teravalidate will validate it later.
d. Running teravalidate –
Command – hadoop jar hadoop-mapreduce-examples.jar teravalidate /benchmarks/terasort-output /benchmarks/terasort-validate.
This command just ensures if the output of terasort was valid and without error.
3. TestDFSIO
TestDFSIO is a test for IO throughput of the cluster.
- Write creates sample files,
- Read reads them, and
- Clean deletes the test outputs.
Benchmarking TestDFSIO
a. Run write command – hadoop jar hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 1000 // Write 10 1GB files.
This automatically creates a folder under /benchmarks/TestDFSIO where it writes out these files.
b. Run read command – hadoop jar hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 1000.
This reads the files produced by the -write step to read throughput.
c. Run clean command – hadoop jar hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO –clean.
This cleans out the /benchmarks/TestDFSIO folder in the HDFS.
4. Intel HiBench
HiBench is a big data benchmark suite that helps evaluate different big data frameworks in terms of speed, throughput and system resource utilizations. It contains a set of Hadoop, Spark and streaming workloads, including Sort, WordCount, TeraSort, Sleep, SQL, PageRank, Nutch indexing, Bayes, Kmeans, NWeight and enhanced DFSIO, etc. It also contains several streaming workloads for Spark Streaming, Flink, Storm and Gearpump.
Using and extending HiBench suite (which is a big data benchmark by ‘intel’), enhanced DFSIO tests the HDFS’s throughputs of Hadoop tasks, performing read and write operation simultaneously.
WordCount
This workload counts the occurrence of each word in the input data, which are generated using RandomTextWriter. It is representative of another typical class of real world MapReduce jobs – extracting a small amount of interesting data from large data set.
Sleep
This workload sleeps for some seconds in each task to test framework scheduler.
Benchmarking Spark –
Run SparkBench is the tool for benchmarking the spark.
To run a single workload (WordCount):
- bin/workloads/micro/wordcount/prepare/prepare.sh
- bin/workloads/micro/wordcount/spark/run.sh
The prepare.sh launches a Hadoop job to generate the input data on HDFS. The run.sh submits the Spark job to the cluster. Bin/run_all.sh can be used to run all workloads listed in conf/benchmarks.lst.
The <HiBench_Root>/report/hibench.report is a summarized workload report,including workload name, execution duration, data size, throughput per cluster, throughput per node.
Streaming Benchmarks:
Identity – This workload reads input data from Kafka and then writes result to Kafka immediately, there is no complex business logic involved.
Repartition – This workload reads input data from Kafka and changes the level of parallelism by creating more or fewer partitionstests. It tests the efficiency of data shuffle in the streaming frameworks.
Stateful Wordcount – This workload counts words cumulatively received from Kafka every few seconds. This tests the stateful operator performance and Checkpoint/Acker cost in the streaming frameworks.
Fixwindow – The workloads performs a window based aggregation. It tests the performance of window operation in the streaming frameworks.
Websearch Benchmarks:
PageRank – This workload benchmarks PageRank algorithm implemented in Spark-MLLib/Hadoop (a search engine ranking benchmark included in pegasus 2.0) examples. The data source is generated from Web data whose hyperlinks follow the Zipfian distribution.
Nutch indexing – Large-scale search indexing is one of the most significant uses of MapReduce. This workload tests the indexing sub-system in Nutch, a popular open source (Apache project) search engine. The workload uses the automatically generated Web data whose hyperlinks and words both follow the Zipfian distribution with corresponding parameters. The dict used to generate the Web page texts is the default linux dict file.
This blog introduces the need for specialized tools for benchmarking Big Data products. Different tools and methods were introduced. We will continue this blog series and add specific test commands with Lab setup. We understand the need to also present our performance results for common benefit of the Big Data community. Our present study does reveal gaps in present testing tools and approach towards Big Data and its unique demands from workloads.
[Tweet “Basics of #BigData Performance Benchmarking ~ via @CalsoftInc”]





