Machine learning is about using data to build intelligent artifacts that learn over time. It involves collecting and analysing large amounts of data to extract information using various computational structures and algorithms.
Machine learning algorithms can be classified broadly into 3 categories:
Supervised Learning – Labelled data sets that are used to infer functions for labelling new data
Unsupervised Learning – Input data sets that are used to derive onto some structure of data and provide concise description of data. This leads to classification of data is some way.
Reinforcement Learning – Learning policies which provide specific directions to take actions based on delayed rewards and interactions with the environment
Let’s delve further into supervised learning
Supervised Machine Learning
Most of the supervised machine learning algorithms try to develop or build a model. The models can be described as a prediction system which use labelled historical data to train themselves for labelling future data.
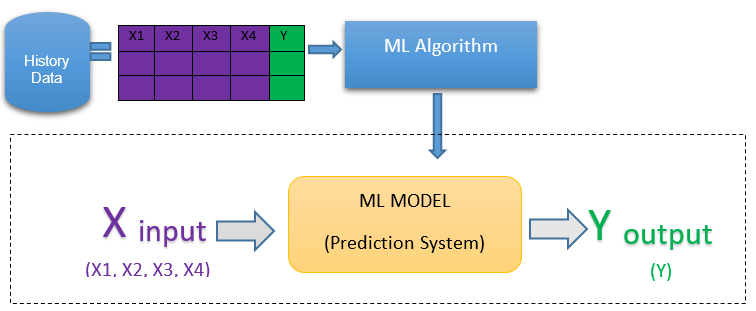
As seen in figure 1, we typically have historical data which is run through some supervised machine learning algorithm to build a prediction system or model. Then at the time of using the model, an input X is given to the system which can be a set of observations that predicts an output Y.
The input X can be multidimensional, a combination of multiple factors and maybe some set of labelled observations which can be used to generate a prediction Y. Following are a few examples to illustrate:
- Prediction of stock prices – Multiple factors like today’s closing price, sharpe ratio, volume traded , Bollinger band values can all be input factors (X values) to predict the future price of stock (Y value). Training data is historical stock trading data.
- Predict the recommended items for e-commerce apps– input factors like user age , gender, demographic details , last shopped item(X values) can act as input factors to predict recommended items (Y value) which user are likely to buy. Previous shopping history and user details can be used for training the system.
Supervised learning is about making assumptions and defining a well behaved function which is consistent with the data so we can generalize for future data. Its induction, goes from specific data to generalized rule using function approximation.
There are two types of supervised learning:
- Regression –Taking a set of inputs and getting a numerical prediction or a continuous value using a mapping function.
- Classification – Taking some kind of input and mapping it to a discrete label from a set of labels.
Given below are 2 examples that explain the difference between classification and regression
| Input Data | Classification | Regression |
| Credit History | Return output Yes/No if bank should lend money depending on credit history.
Labels – Yes/No |
Return the max amount of money bank can lend depending on credit history
Return value – Exact lending amount
|
| Photo of a person | Identify from photo if the person is in elementary school , college or senior care facility
Labels – school, college , senior care
|
Identify the exact age of a person from photo e.g. 17 years , 48 years
Return value – Exact age |
Table 1: Classification vs Regression Examples
There are different supervised learning algorithms which differ in multiple ways w.r.t performance during training vs performance during query, whether data is kept or discarded after a model is built, how easily a model can be updated when new data comes up. Table 2 lists few different algorithms used to build different supervised ML models used:
| Parametric Regression | A model is represented with a number of parameters. This includes linear regression and polynomial regression.
|
| Decision Trees | A decision tree model is built using data and can be used in classification and regression scenarios
|
| Instance based | KNN and kernel regression are data-centric models where the data is preserved and is used later when querying the model.
|
| Neural Networks | Perceptron training model which uses a linear threshold units and learning rules to put together a network which produces a Boolean function |
Table 2: Supervised Machine Learning Algorithms
More about the algorithms in future blogs!





